Marketing
Big Data: Was ist das und wie funktioniert es?
Wer Marketing in den 2020er Jahren erfolgreich betreiben will, der kommt um Big Data nicht mehr herum. Wir erklären Ihnen, was Big Data überhaupt ist.

Marketing
Wir haben es mit immer mehr und mehr Daten zu tun. Wir speichern mehr Informationen für jeden einzelnen Menschen, und wir beginnen sogar auch damit, mehr Informationen von Geräten zu speichern. Das Internet der Dinge existiert wirklich und schon bald wird auch Ihre Kaffeemaschine Ihre Trinkgewohnheiten hinsichtlich des Kaffees nachverfolgen und in der Cloud speichern.
Big Data nimmt dabei eine essentielle Stellung ein. Was Big Data genau ist und wie es funktioniert, das erfahren Sie in diesem Artikel.
Der Begriff Big Data tauchte erstmals in den 1960er Jahren auf, gewinnt aber heutzutage eine neue Bedeutung.
Wissen Sie, dass ein Düsentriebwerk innerhalb von 30 Flugminuten über Terabyte an Daten erzeugen kann? Und wie viele Flüge gibt es pro Tag?
Das sind Tag für Tag Petabyte von Informationen. Die New Yorker Börse generiert täglich etwa ein Terabyte neuer Handelsdaten.
Durch das Hochladen von Fotos und Videos, Nachrichten und Kommentaren auf Facebook werden täglich mehr als 500 Terabyte an neuen Daten generiert. Diese extrem große Menge an Daten nennen wir Big Data.
Big Data wird immer mehr zu einem untrennbaren Bestandteil unseres Lebens. Jeder nutzt irgendeine Art von Technologie oder kommt mit Produkten und großen Unternehmen in Kontakt.
Diese großen Unternehmen bieten uns ihre Daten an und verwenden gleichzeitig auch die Daten, die wir ihnen anbieten. Diese Daten werden von den Unternehmen ständig analysiert, um effizienter produzieren und neue Produkte entwickeln zu können.
Um Big Data wirklich zu verstehen, ist es hilfreich, etwas über seine Geschichte zu wissen.
Per Definition besteht Big Data aus Daten, die eine größere Vielfalt enthalten und in zunehmendem Umfang eingehen, und letztendlich mit immer höherer Geschwindigkeit.
Deshalb sprechen wir, wenn wir uns über Big Data unterhalten, immer von den „großen Vs (Merkmalen)“ von Big Data. Davon gibt mittlerweile mehr als drei, weil sich das hinter Big Data stehende Konzept weiterentwickelt hat.
Datenspeicher sind heutzutage wesentlich preiswerter als noch vor ein paar Jahren – und das macht es einfacher und kostengünstiger, größere Datenmengen zu speichern. Aber warum benötigt man so viele Daten?
Nun, Daten können Sie bei vielen Dingen unterstützen – Präsentieren Sie diese Daten Ihren Kunden, verwenden Sie sie für die Entwicklung neuer Produkte, Geschäftsentscheidungen und vieles mehr.
Der Name Big Data ist nicht so neu, aber das Konzept für den Umgang mit großen Datenmengen ändert sich. Was wir vor einigen Jahren Big Data nannten, bestand aus weit weniger Daten als heute. Es begann in den 1960er Jahren, als die ersten Data Warehouses eröffnet wurde.
Vierzig Jahre später erkannten Unternehmen, wie viele Datensätze über Online-Dienste, Webseiten, Anwendungen und Produkte erfasst werden konnten, mit denen Kunden interagieren.
Zu dieser Zeit gewannen die ersten der Big Data-Dienste an Popularität zu gewinnen (Hadoop, NoSQL usw.). Das Vorhandensein solcher Werkzeuge war obligatorisch, da sie das Speichern und Analysieren von Big Data einfacher und billiger machten.
Das Internet der Dinge ist heute nicht mehr nur ein Traum. Immer mehr Geräte sind mit dem Internet verbunden und erfassen Daten zu den Nutzungsmustern der Kunden und zur Produktleistung. So entstand das maschinelle Lernen, was auch wiederum zu einer Generierung von Daten führte.

Können Sie sich vorstellen, wie viele Daten das sind? Und können Sie sich vorstellen, wie viele Verwendungszwecke es für all diese Daten gibt?
Wenn Sie über so viele Daten verfügen, können Sie bessere Entscheidungen treffen weil Sie alle Informationen haben, die Sie jemals benötigen könnten. Sämtliche Probleme und Schwierigkeiten können problemlos gelöst werden.
Mit einfachen Worten, Big Data besteht aus größeren und komplexeren Datensätzen, die größtenteils aus neuen Datenquellen stammen. Diese Datengruppen sind so umfangreich, dass die herkömmliche, für die Datenverarbeitung verwendete Software sie nicht einfach verwalten konnte, sodass eine neue Reihe von Tools und Software geschaffen wurde.
Da es sich bei Big Data um etwas handelt, das stetig weiter wächst, werden auch die Tools, die für diesen Bereich vorgesehen sind ständig weiterentwickelt und verbessert. Je nach Anforderungsprofil des Unternehmens werden Tools wie Hadoop, Pig, Hive, Cassandra, Spark, Kafka usw. verwendet.
Es gibt so viele Lösungen, und ein großer Teil davon ist Open-Source. Es gibt auch eine Stiftung – die Apache Software Foundation (ASF), die viele dieser Big-Data-Projekte unterstützt.
Da diese Tools für Big Data von großer Bedeutung sind, werden wir zu einigen davon ein paar Worte sagen. Eines der vielleicht etabliertesten Tools für die Analyse von Big Data ist Apache Hadoop, ein Open-Source-Framework zum Speichern und Verarbeiten großer Datenmengen.
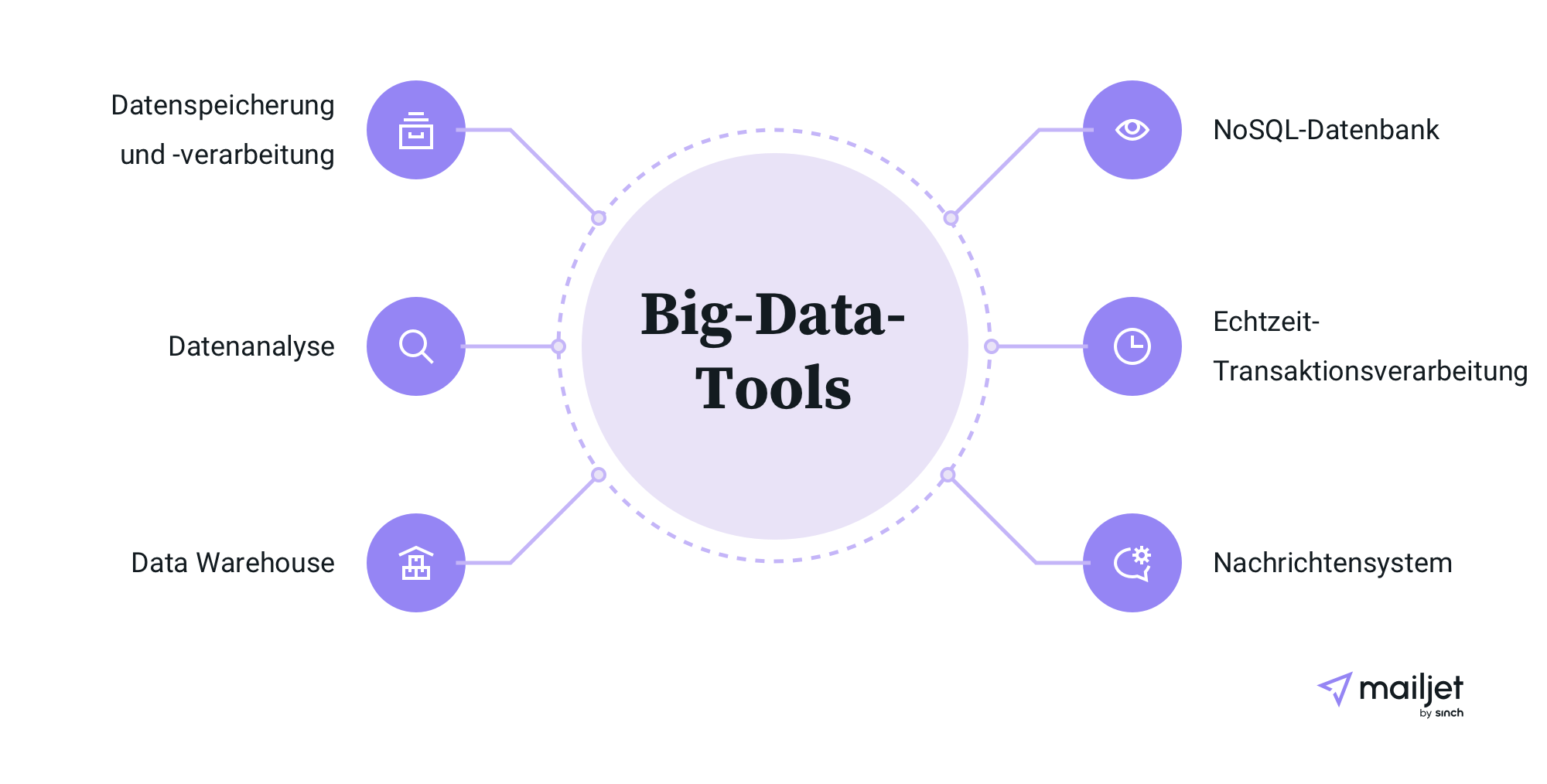
Ein weiteres Tool, das immer mehr Aufmerksamkeit auf sich zieht, ist Apache Spark. Eine der Stärken von Spark ist die, dass es einen großen Teil der Verarbeitungsdaten im Speicher und auf der Festplatte speichern kann, was im Normalfall eine wesentlich höhere Geschwindigkeit erzielt.
Spark ist mit Hadoop (Hadoop Distributed File System), Apache Cassandra, OpenStack Swift und vielen anderen Datenspeicherlösungen kompatibel. Aber eines der herausragenden Merkmale von Spark ist, dass Spark auf einem einzelnen lokalen Computer ausgeführt werden kann und das macht die Arbeit damit so viel einfacher.
Eine andere Lösung ist Apache Kafka, mit dem die Benutzer Echtzeit-Datenfeeds veröffentlichen und abonnieren können. Die Hauptaufgabe von Kafka besteht darin, die Zuverlässigkeit anderer Nachrichtensysteme für das Streaming von Daten zu verbessern.
Weitere Big-Data-Tools sind:
Big Data wird weiter wachsen und sich verändern und das bedeutet, dass es die Tools auch tun werden. Und vielleicht werden die Strukturen die wir in ein paar Jahren verwenden, vollkommen anders sein. Wie bereits erwähnt, arbeiten einige Tools mit strukturierten oder unstrukturierten Daten. Sehen wir uns einmal an, was das bedeutet.
Hinter Big Data stehen drei Arten von Daten – strukturierte, halbstrukturierte und unstrukturierte Daten. Jede Art beinhaltet viele nützliche Informationen, die Sie abrufen können, um sie dann in verschiedenen Projekten zu verwenden.
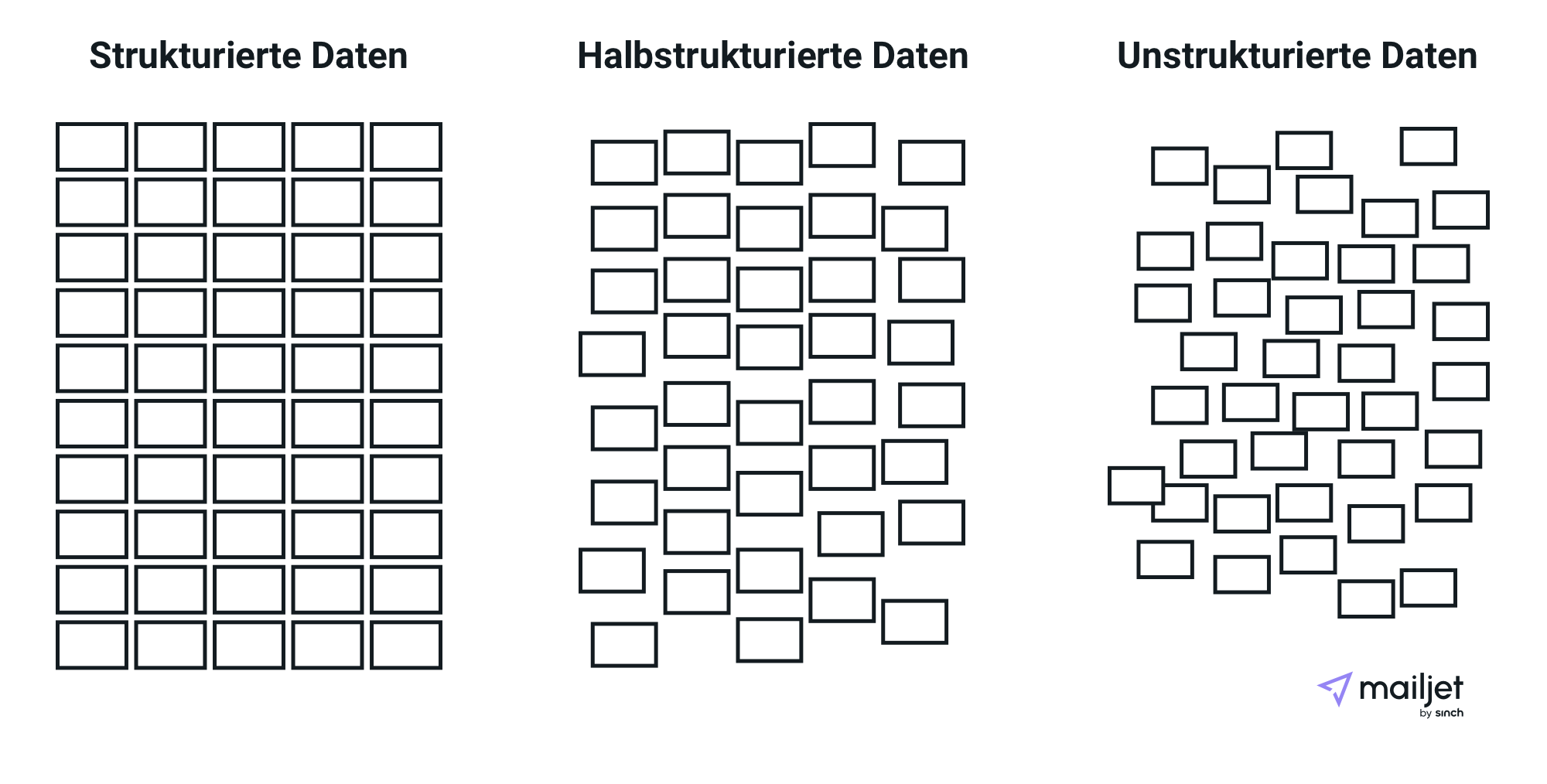
Strukturierte Daten liegen in einem festen Format vor und sind naturgemäß häufig numerisch. In den meisten Fällen werden diese Daten daher von Computern gehandhabt und nicht Menschen.
Diese Art von Daten besteht aus Informationen, die bereits vom Unternehmen in Datenbanken und Tabellenkalkulationen verwaltet werden, die in SQL-Datenbanken, Data Lakes und Data Warehouses gespeichert sind.
Unstrukturierte Daten sind Information, die unorganisiert sind und nicht in einem vorbestimmten Format vorliegen, da es sich um die verschiedenartigsten Daten handeln kann.
Sie enthalten beispielsweise Daten aus sozialen Medien, die in Textdokumenten abgelegt werden, die in Hadoop wie Cluster oder NoSQL-Systeme gespeichert sind.
Teilstrukturierte Daten können beide Formen von Daten enthalten, wie z. B. Webserver-Protokolle oder Daten von Sensoren, die Sie eingerichtet haben.
Genau genommen bezieht es sich auf die Daten, die zwar nicht in ein bestimmtes Repository (Datenbank) eingestuft wurden, jedoch wichtige Informationen oder Tags enthalten, die einzelne Elemente in den Daten trennen.
Big Data umfasst immer mehrere Quellen und wird zum größten Teil auch von unterschiedlichen Arten gespeist. Es ist daher nicht immer einfach, alle Tools zu integrieren, die Sie für die Arbeit mit den verschiedenen Typen benötigen.
Der wichtigste Gedanke hinter Big Data ist der, dass je mehr Sie über alles wissen, desto mehr Einblicke werden Sie gewinnen und eine Entscheidung treffen oder eine Lösung finden können.
In den meisten Fällen ist dieser Prozess vollständig automatisiert – wir verfügen über so fortschrittliche Tools, die Millionen von Simulationen ausführen, um für uns das bestmögliche Ergebnis zu erzielen.
Um dies jedoch mithilfe von Analyse-Tools, maschinellem Lernen oder sogar künstlicher Intelligenz zu erreichen, müssen Sie wissen, wie Big Data funktioniert, und alles korrekt einrichten.
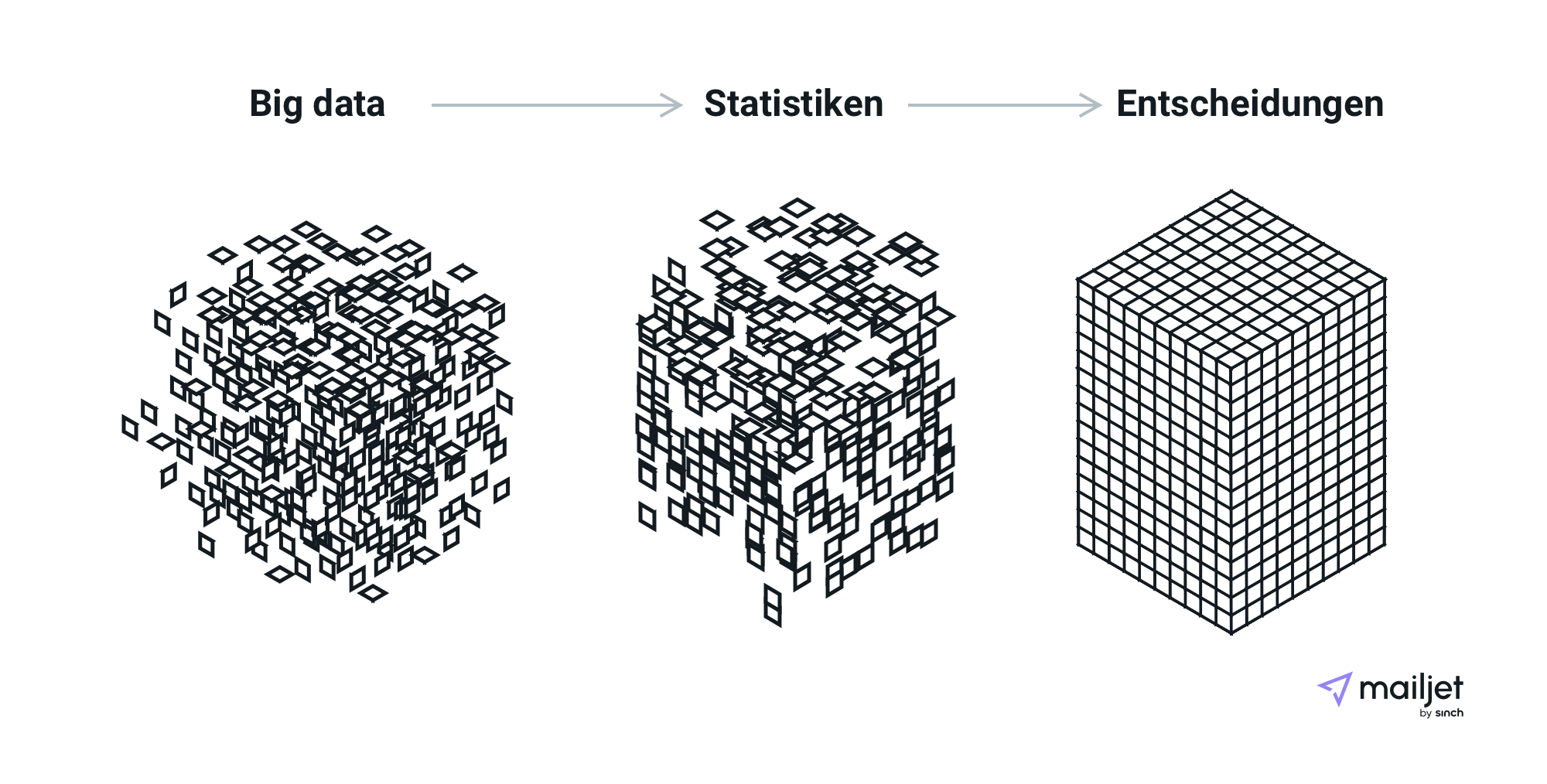
Der notwendige Umgang mit einer solchen Menge an Daten erfordert eine sehr stabile und gut strukturierte Infrastruktur. Sie muss schnell große Volumina und unterschiedliche Datentypen verarbeiten können, was einen einzelnen Server oder Cluster leicht überlasten kann.
Aus diesem Grund benötigen Sie für Big Data ein gut durchdachtes System.
Alle Prozesse sollten entsprechend der Kapazität des Systems berücksichtigt werden. Und dies kann für größere Unternehmen möglicherweise Hunderte oder Tausende von Server erfordern. Wie Sie sich vorstellen können, kann das sehr teuer werden. Und wenn Sie jetzt noch alle benötigten Tools hinzufügen, wird es sich schnell summieren.
Daher müssen Sie wissen, wie Big Data funktioniert und die drei zentralen Aktionen dahinter kennen, damit Sie Ihr Budget im Voraus planen und das bestmögliche System aufbauen können.
Bei Big Data werden Daten aus mehreren unterschiedlichen Quellen zusammengeführt und da wir hier über enorme Mengen an Informationen sprechen, werden neue Strategien und Technologien benötigt.
In manchen Fällen sprechen wir hier über Petabyte an Informationen, die in Ihr System fließen, wodurch es zur Herausforderung wird, ein solches Informationsvolumen in Ihr System zu integrieren.
Sie müssen die Daten empfangen, verarbeiten und in die geeignete Form formatieren, in der Ihr Unternehmen diese benötigt und die Ihre Kunden verstehen können.
Was benötigen Sie sonst noch für ein so großes Volumen an Informationen? Sie werden einen Platz brauchen, um die Daten zu speichern. Ihre Speicherlösung kann sich in der Cloud, vor Ort oder in beiden Umgebungen befinden.
Sie können außerdem auswählen, in welcher Form Ihre Daten gespeichert werden, damit Sie sie jederzeit in Echtzeit abrufen können.
Aus diesem Grund entscheiden sich immer mehr Menschen für eine Cloud-Lösung für die Speicherung, da sie Ihre aktuellen Leistungsanforderungen unterstützt.
In Ordnung, Sie haben die Daten empfangen und gespeichert, aber Sie müssen jetzt noch analysiert werden, damit sie genutzt werden können. Durchsuchen und nutzen Sie Ihre Daten, um wichtige Entscheidungen zu treffen, z. B. um zu erfahren, welche Funktionen von Ihren Kunden am häufigsten recherchiert werden, oder um Forschungsergebnisse auszutauschen.
Sie können mit den Daten tun, was Sie sollen – lassen Sie die Daten für sich arbeiten. Sie haben eine große Investition getätigt, um diese Infrastruktur einzurichten, daher sollte sie auch umfangreich genutzt werden.
Wenn wir, wie bereits erwähnt, von Big Data sprechen, sprechen wir auch immer von den großen 5 V (Merkmalen) dahinter. Als Big Data das erste Mal auftauchte, gab es nur 3 V, aber heute sind es mehr. Und es werden immer mehr, je nachdem, wofür Sie Big Data benötigen. Wir werden einige der V im nächsten Teil des Artikels erörtern.
Wie der Name schon sagt, sprechen wir bei Big Data über hohe Volumen an Datenmengen. Von Bedeutung ist also die Menge an Daten, die Sie empfangen. Dies können Daten mit unbekanntem Wert sein, z. B. Daten zur Anzahl der Klicks auf einer Webseite oder einer mobilen App.
Bei manchen Unternehmen können es Dutzende von Terabyte sein, bei anderen Hunderte von Petabyte. Oder Sie kennen die Quelle und den Wert der Daten genau, die Sie erhalten, aber wir sprechen immer noch von enormen Datenvolumen, die Sie täglich erhalten werden.
Geschwindigkeit ist das große V, das repräsentiert, mit welcher Geschwindigkeit die Daten empfangen und verarbeitet werden.
Wenn die Daten direkt in den Speicher gestreamt und nicht auf eine Festplatte geschrieben werden, bedeutet dies, dass die Geschwindigkeit höher ist und Sie entsprechend schneller arbeiten und Daten nahezu in Echtzeit bereitstellen können.
Dies erfordert jedoch auch die Möglichkeit, die Daten in Echtzeit auswerten zu können.
Geschwindigkeit ist auch das große V, das für Bereiche wie maschinelles Lernen und künstliche Intelligenz von größter Bedeutung ist.
Variety bezieht sich auf die Arten von Daten, die verfügbar sind. Wenn Sie mit so vielen Daten arbeiten, müssen Sie wissen, dass ein großer Teil davon unstrukturiert und halbstrukturiert ist (Text, Audio, Video usw.).
Es wird eine zusätzliche Verarbeitung der Metadaten erforderlich sein, um die Daten für alle verständlich zu machen.
Wahrhaftigkeit bezieht sich darauf, wie exakt die Daten in den Datensätzen sind. Sie können eine Menge Daten aus sozialen Medien oder Webseiten sammeln, aber wie können Sie sicher sein, dass die Daten genau und korrekt sind?
Daten von geringer Qualität und ohne Überprüfung können zu Problemen führen. Nicht einwandfreie Daten können zu ungenauen Analysen und zu Fehlentscheidungen führen.
Infolgedessen müssen Sie Ihre Daten immer überprüfen und sicherstellen, dass Sie über genügend exakte Daten verfügen, um gültige und aussagekräftige Ergebnisse zu erhalten.
Wie bereits erwähnt, sind nicht alle gesammelten Daten von Wert und können so auch nicht durchweg für geschäftliche Entscheidungen verwendet werden. Es ist wichtig, den Wert der Daten zu kennen, die Ihnen zur Verfügung stehen.
Und Sie müssen Maßnahmen zur Bereinigung Ihrer Daten veranlassen und bestätigen, dass die Daten für den aktuellen Verwendungszweck von Relevanz sind.
Wenn Sie über viele Daten verfügen, können Sie die diese tatsächlich für mehrere Zwecke verwenden und auf verschiedene Weise formatieren. Es ist nicht einfach, so viele Daten zu sammeln, sie zu analysieren und sinnvoll zu verwalten.
Daher ist es normal, sie mehrmals zu verwenden. Dafür steht die Variability: Die Option, die Daten für mehrere Zwecke verwenden zu können.
Wir wissen jetzt viel über Big Data – aus was es besteht, die Arten von Daten und den großen Vs. Aber das ist für uns nicht wirklich von Nutzen, wenn wir nicht wissen, was Big Data kann und warum es immer wichtiger wird.
Big Data hat viel Potenzial. Sie können die wertvollen Erkenntnisse, die diese Daten bereitstellen, für Ihre Entscheidungen im Marketingbereich hinsichtlich Ihres Produkts und Ihrer Marke nutzen.
Marken, die Big Data nutzen, können schnellere und fundiertere Geschäftsentscheidungen treffen. Mit all den Informationen über Ihre Kunden können Sie Ihr Produkt kundenorientierter gestalten und maßgeschneiderte Inhalte für Ihre Kunden schaffen oder ihre Customer Journey personalisieren.
Entscheidungen zu treffen, wenn Sie über alle benötigten Informationen verfügen, ist einfacher, oder?
Stellen Sie sich zum Beispiel vor, wie nützlich Big Data in der medizinischen Forschung ist, um zu ermitteln, wie gefährlich es sein kann, an bestimmten Krankheiten zu erkranken, abhängig von persönlichen medizinischen Informationen oder dem Wissen, wie bestimmte Krankheiten behandelt werden sollten.
Dies ist nur ein Beispiel für die Verwendung von Big Data, aber eines der wichtigsten.
So etwas wie Online-Dating könnte mehr als 90 % exakt sein, sobald Computer lernen, Paare anhand der Informationen, über die sie für diese beiden Personen verfügen, perfekt zuzuordnen.
Rechnerausfälle oder Abstürze können minimiert werden, weil Sie wissen, unter welchen Bedingungen die Fehler auftreten. Sie können ein Auto entwickeln, das selbst fährt, und es ist sicherer als jedes andere Auto, das von einer realen Person gefahren wird, weil es keine menschlichen Fehler macht.
Es analysiert Big Data-Informationen in Echtzeit und kennt die beste Route, um pünktlich zum Ziel zu gelangen.
Basierend auf der über Ihre Kunden verfügbaren Informationen können Unternehmen jetzt genau prognostizieren, welche Segmente ihrer Kunden ihre Produkte kaufen möchten und zu welcher Zeit, sodass sie den besten Zeitpunkt für die Veröffentlichung kennen.
Und Big Data unterstützt die Unternehmen dabei, ihre Abläufe effizienter zu gestalten.
Big Data ist wichtig für den Fortschritt unserer Technologie und es kann unser Leben leichter machen, wenn wir es mit Bedacht und dauerhaft einsetzen. Das Potenzial von Big Data ist endlos. Sehen wir uns einmal ein paar Anwendungsfälle an.
Die Analyse von Big Data kann je nach Ihren Anforderungen von Menschen und Maschinen durchgeführt werden.
Mit verschiedenen analytischen Mitteln können Sie verschiedene Arten von Daten und Quellen kombinieren, um so sinnvolle Entdeckungen zu machen und Entscheidungen zu treffen.
So können Sie Ihre Produkte schneller veröffentlichen und die richtige Zielgruppe ansprechen. Unten sehen Sie einige der häufigsten Anwendungsmöglichkeiten von Big Data.
Wenn Ihr Hauptgeschäft Ihr Produkt ist, ist Big Data für Sie mehr als obligatorisch. Nehmen wir ein Beispiel, das fast jeder kennt – Netflix. Wie schafft es Ihrer Meinung nach Netflix, Ihnen jede Woche eine E-Mail mit Empfehlungen zu senden, die speziell für Sie ausgewählt wurden?
Mithilfe der Big Data-Analyse natürlich. Sie verwenden Vorhersagemodelle und informieren Sie über neue Sendungen, die Ihnen gefallen könnten, indem sie die Daten vergangener und aktueller Sendungen klassifizieren, die Sie sich angesehen oder als Favorit markiert haben.
Andere Unternehmen nutzen zusätzliche Ressourcen wie Informationen aus den sozialen Medien, Verkaufsinformationen, Gesprächsgruppen, Umfragen, Tests und vieles mehr, um zu erfahren, wie bei der Veröffentlichung eines neuen Produkts vorzugehen ist, und auf welche Zielgruppe man sich konzentrieren sollte.
Wenn Sie Bescheid wissen, wie sich Ihre Kunden verhalten und sie in Echtzeit beobachten können, können Sie dies vergleichen mit den Customer Journeys ähnlicher Produkte und Sie werden erkennen, in welchen Punkten Sie stärker abschneiden als Ihre Konkurrenten.

Der Markt ist so groß, dass es schwierig ist, ein Produkt als einzigartig hervorzuheben. Was können Sie also tun, um sich von anderen abzuheben? Bemühen Sie sich, die Erfahrungen Ihrer Kunden zu personalisieren.
Mit Big Data können Sie Daten aus sozialen Netzwerken, aufgerufene Seiten im Web, Anrufprotokolle und andere Quellen erfassen, um die Interaktion zu verbessern und den erzielten Nutzen zu maximieren.
Maschinelles Lernen ist gerade sehr im Trend und jeder möchte mehr darüber wissen. Wir sind heute in der Lage Maschinen zu schaffen, die selbstständig lernen können, und die die Fähigkeit, dies tun zu können, verdanken wir Big Data und den Modellen für das maschinelle Lernen, die auf der Basis von Big Data entwickelt werden konnten.
Jederzeit zu wissen, welcher Teil Ihrer Infrastruktur mobilisiert werden muss oder die Möglichkeit, mechanische Ausfälle prognostizieren zu können ist von hoher Bedeutung. Die Analyse der Daten wird zunächst nicht einfach sein, da Sie sowohl mit strukturierten (Zeiträume, Geräte) als auch mit unstrukturierten Daten (Protokolleinträge, Fehlermeldungen usw.) überhäuft werden.
Wenn Sie jedoch alle Angaben berücksichtigen, können Sie potenzielle Probleme erkennen, bevor sie auftreten, oder den Einsatz Ihrer Ressourcen skalieren.
Mit Big Data können Sie Kundenfeedback analysieren und zukünftige Anforderungen prognostizieren, sodass Sie immer wissen, wann weitere Ressourcen benötigt werden.
Hacking… wir alle hassen es, aber es passiert immer öfter. Jemand versucht, sich als Ihre Marke auszugeben, jemand versucht, Ihre Daten und die Daten Ihrer Kunden zu stehlen… Und die Hacker werden von Tag zu Tag kreativer.
Das gilt aber auch für Sicherheits- und Compliance-Anforderungen – sie ändern sich ständig. Mit Big Data können Sie Muster in diesen Daten identifizieren, die auf einen Betrug hinweisen, und wissen so, wann und wie Sie reagieren müssen.
Ihre Datenanalysten werden mehrere Nutzungszwecke für Ihre Daten finden und herausfinden, wie Sie die verschiedenen Datentypen verbinden können, über die Sie verfügen.
Sie können diese Daten verwenden, um offizielle Forschungsergebnisse zu veröffentlichen und mehr Aufmerksamkeit auf Ihre Marke zu lenken.
Big Data verändert bereits jetzt so vieles und wird auch in der Zukunft zweifelsohne weiter wachsen. Stellen Sie sich vor, wie sehr dies unser Leben in Zukunft verändern kann!
Sobald alles um uns herum damit beginnt, das Internet (Internet der Dinge) zu nutzen, wird das die Möglichkeiten zur Nutzung von Big Data enorm anwachsen lassen.
Die uns zur Verfügung stehende Datenmenge wird noch weiter zunehmen und die Analysetechnologie noch fortschrittlicher werden. Big Data ist eines der Dinge, die die Zukunft der Menschheit prägen werden.

Aber auch die für Big Data verwendeten Tools werden sich weiterentwickeln. Die Anforderungen an die Infrastruktur werden sich ändern. Vielleicht können wir in Zukunft alle von uns benötigten Daten auf nur einem Rechner speichern und dieser hat mehr als genug Speicherplatz.
Dies könnte möglicherweise alles billiger machen und unsere Arbeit erleichtern. Big Data ist eines der Themen, an denen wir bei Mailjet interessiert sind, und wir werden es mit Sicherheit weiter verfolgen.
Wenn Sie mehr darüber erfahren möchten, wie wir Big Data einsetzen und welche Tools wir verwenden, sollten Sie unseren kostenlosen Newsletter abonnieren, um als Erster unseren nächsten Artikel zu diesem Thema zu lesen.
Die Reichweite und die Möglichkeiten von Big Data wären vor einiger Zeit noch unvorstellbar gewesen. Heutzutage gibt es jedoch kaum eine technologische Innovation, die nicht davon beherrscht wird.
Aber seien wir ehrlich – zu verstehen, was Big Data ist und wie es funktioniert, ist keine leichte Aufgabe. Wir wissen, dass es eine Menge Informationen sind, die Sie behalten müssen. Deshalb haben wir die wichtigsten Aspekte in einer praktischen Infografik zusammengefasst.
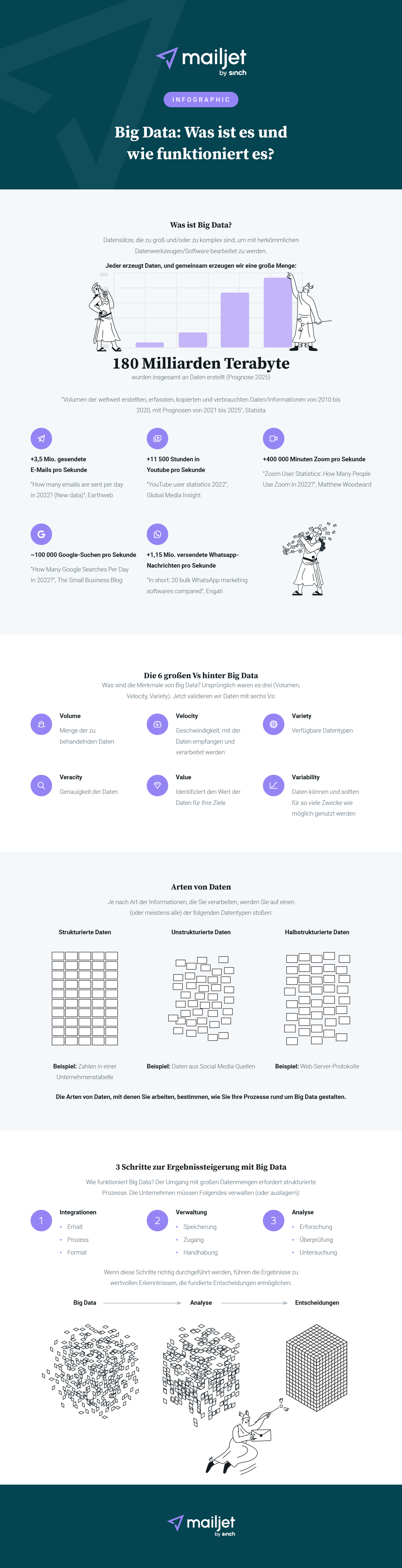
***
Dies ist die überarbeitete Version eines Artikels, der ursprünglich von Gabriela Gavrailova am 3. Dezember 2019 verfasst wurde.



