Big Data: ¿Qué es, cómo funciona y por qué es importante?
¿Te suena haber oído hablar de ello pero no sabes exactamente qué es el Big Data? No te preocupes, aquí te contamos en qué consiste, cómo funciona, para qué se usa y por qué es (y va a ser) tan importante.
¿Qué es el Big Data?, ¿para qué se utiliza?, o ¿cuáles son las “v” del Big Data? Estas son algunas de las preguntas que puedes tener si te estás preguntando por qué los datos se han convertido en el petróleo de la era digital para las organizaciones de todo el mundo.
Cada día se generan más datos. El Internet de las Cosas (IoT, por sus siglas en inglés) no es algo imaginario y ya puedes rastrear tus hábitos de compra, de sueño o la cantidad de calorías que quemas cuando sales a correr. El término Big Data apareció por primera vez en los años sesenta, pero ahora está cobrando una nueva importancia.
En este artículo vamos a intentar resolver todas tus dudas y preguntas. ¡Toma nota!
Por definición, el Big Data (o macrodatos) son conjuntos de datos de gran variedad, que se generan en grandes volúmenes y a una velocidad cada vez mayor. Por eso, cuando hablamos del Big Data, siempre mencionamos las tres “V” del Big Data. Bueno, en realidad ahora hay más de tres “V”, porque el concepto del Big Data ha evolucionado, pero eso lo explicamos más abajo.
¿Sabías que el motor de un avión genera más de 10 terabytes de datos en solo 30 minutos de vuelo? ¿Y cuántos vuelos hay en un día? Esto hace que cada día haya varios petabytes nuevos de información. Las cargas de fotos y vídeos, los mensajes y los comentarios en Facebook generan varios cientos de terabytes de datos nuevos a diario. La suma de todo esto se estima que en 2025 superará el total de 180 zettabytes (o 180 billones de gigabytes). Pues eso es a lo que llamamos Big Data.
En resumidas cuentas, el Big Data son datos. Muchos datos. Nuestra sociedad no para de generar datos a una velocidad vertiginosa. Lo que importa es lo que se hace con esos datos. Cómo se almacenan y analizan, y las conclusiones y oportunidades que se obtienen de ellos.
Fuentes de datos: ¿de dónde procede esta gran cantidad de datos?
El Big Data se genera a través de muchas de las actividades que realizamos a diario. Por ello, las fuentes de datos son verdaderamente diversas: dispositivos GPS, sensores de reconocimiento facial o emails son solo algunos ejemplos.
Las fuentes de procedencia más habituales de estos grandes volúmenes de datos son:
Procesamiento de datos: ¿cómo se realiza?
La mayoría de las personas utiliza algún tipo de tecnología o servicio online como Gmail o Facebook. Estas empresas nos permiten que enviemos e intercambiemos datos y, a su vez, utilizan los datos que les ofrecemos.
Es decir, los servicios en línea, sitios web, aplicaciones y muchos otros dispositivos analizan datos constantemente para conseguir que sus servicios sean más eficaces y desarrollar nuevos productos. Y para ello, utilizan herramientas y servicios de Big Data (como Hadoop o NoSQL) para analizar y procesar el gran volumen de datos generados, con el fin de mejorar su oferta. Pero no se queda ahí. Un día alguien pensó: «¿Por qué no usamos los datos masivos para que las máquinas aprendan por sí solas?». Así es como nació el aprendizaje automático, o machine learning, lo que también comenzó a generar más datos.
Datos y más datos, con aplicaciones casi infinitas que te ayudan a tomar decisiones, resolver problemas e incluso escribir una respuesta automática en tu correo o LinkedIn.
Tipos de Big Data
Los datos se pueden clasificar según su estructura, y así podemos distinguir entre:
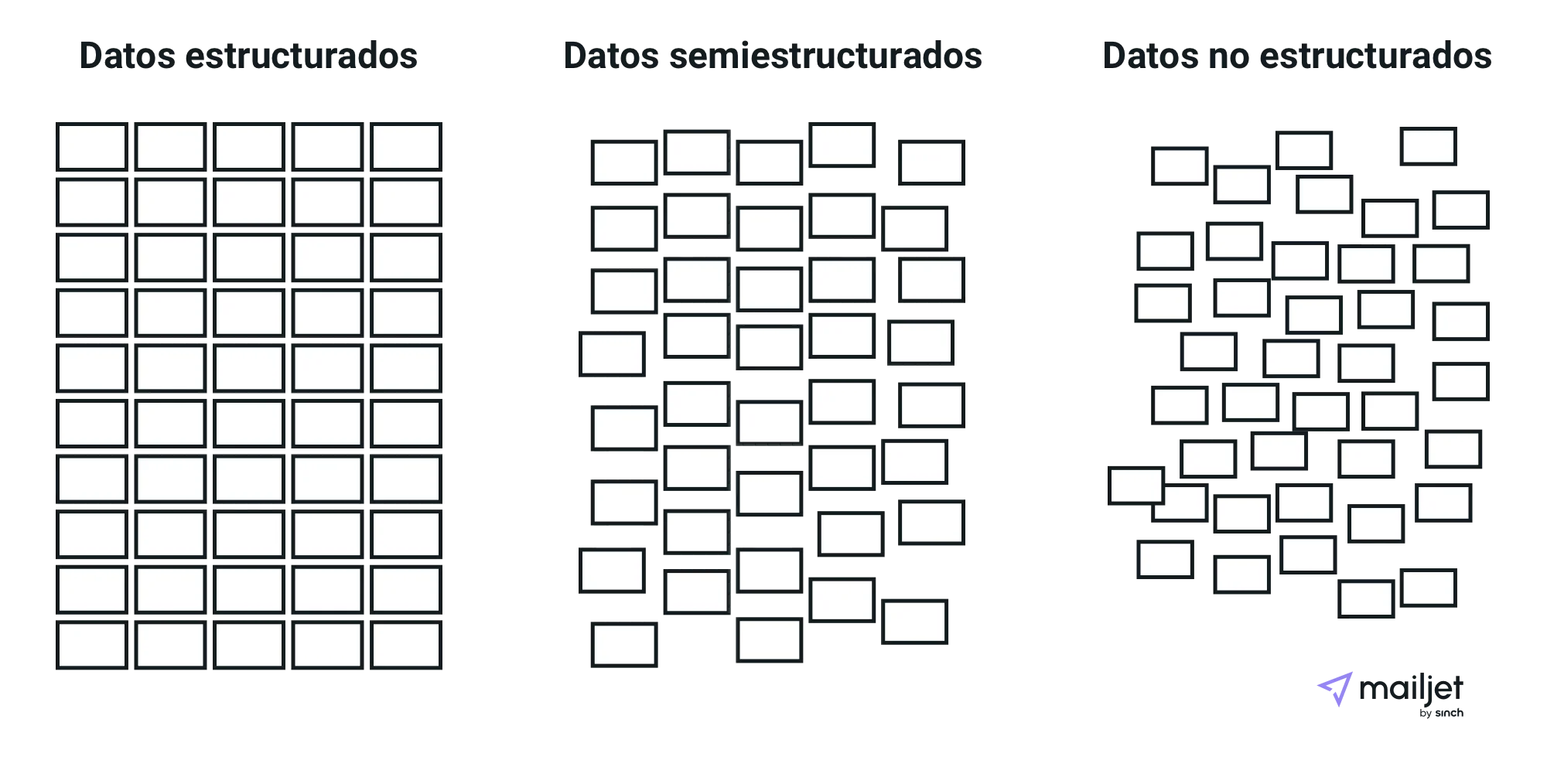
Datos estructurados.
Datos no estructurados.
Datos semiestructurados.
Datos estructurados
Los datos estructurados tienen un formato fijo y a menudo son numéricos. Este tipo de datos es información que ya está ordenada en bases de datos y hojas de cálculo, que están almacenadas en bases de datos SQL, lagos de datos y almacenes de datos. Por ello, en muchos casos, las máquinas (en lugar de los seres humanos) pueden gestionar los datos estructurados con éxito.
Datos no estructurados
Los datos no estructurados es información que carece de organizacióny no está en un formato predeterminado porque puede ser muy diversa. Los datos recopilados de fuentes de redes sociales son un buen ejemplo. Se pueden convertir en archivos de documentos de texto almacenados en Hadoop, como clústeres o sistemas NoSQL.
Datos semiestructurados
Los datos semiestructurados pueden contener ambas formas de datos, como, por ejemplo, los registros de servidores web o los datos de sensores que se hayan configurado. Para ser precisos, son datos que, a pesar de no estar clasificados en un repositorio concreto (una base de datos), contienen información vital o etiquetas que segregan elementos individuales dentro de los datos.
El Big Data habitualmente procede de múltiples fuentes, que además pertenecen a tipos de fuentes diferentes. Por este motivo, no siempre es fácil saber cómo integrar todas las herramientas necesarias para trabajar con distintos tipos de datos.
Las grandes V del Big Data
Ahora que ya sabes cuál es la definición de Big Data, de dónde procede o los tipos diferentes que existen, llegamos a las famosas “V” del Big Data. Los científicos de datos (o data scientists, en inglés) utilizan las “V” para definir el Big Data, y tradicionalmente había tres “V” diferentes: volumen, velocidad y variedad. Pero la lista ha aumentado y no existe un acuerdo sobre cuántas “V” hay (o habrá, porque cada vez hay más “V” que se suman a la lista).
A continuación, definimos las seis “V” más comunes.
Volumen
Como su propio nombre indica, cuando hablamos de Big Data nos referimos a grandes volúmenes de datos. Este volumen es importante para el almacenamiento, el procesamiento y la explotación: cuanto mayor sea el volumen, más complejo será utilizar el Big Data. Así pues, la cantidad de datos es un aspecto muy importante. Algunas empresas pueden procesar decenas de terabytes de datos, mientras que otras pueden tratar cientos de petabytes, por ejemplo, sobre el número de personas que hace clic en su sitio web.
Velocidad
La velocidad es la gran V que representa la rapidez con la que se reciben y tratan los datos. Si los datos se transfieren directamente a la memoria (y no se escriben en un disco) la velocidad será mayor y, gracias a ello, se podrá operar mucho más rápido y los datos se proporcionarán prácticamente en tiempo real. Pero para esto también hace falta una forma de evaluar los datos en tiempo real. La velocidad es la “V” más importante en ámbitos como el aprendizaje automático y la inteligencia artificial.
Variedad
La variedad se refiere a los tipos de datos que hay disponibles. Cuando se trabaja con datos diferentes, muchos de ellos son no estructurados y semiestructurados (texto, audio, vídeo, etc.). Para procesar los datos, en particular los datos no estructurados, se necesitan nuevas tecnologías que faciliten su análisis.
Veracidad
La veracidad se refiere a la exactitud de los datos del conjunto de datos. Se pueden recopilar muchos datos de redes sociales o sitios web, pero ¿cómo es posible asegurarse de que los datos son exactos y correctos? Si se usan datos de mala calidad, pueden causar problemas. Los datos inciertos darán pie a análisis imprecisos y harán tomar decisiones equivocadas. Por este motivo, siempre se deben comprobar los datos para garantizar que se dispone de suficientes datos precisos para obtener resultados válidos y relevantes.
Valor
Como decimos, no todos los datos tienen valor, ni se pueden utilizar para tomar decisiones comerciales. Es importante conocer el valor de los datos disponibles, establecer una forma de limpiar los datos y confirmar que son relevantes para el propósito deseado.
Variabilidad
Cuando se dispone de muchos datos, se pueden utilizar con fines muy distintos. No es fácil recoger tantos datos, analizarlos y gestionarlos apropiadamente, por lo que lo normal es usarlos varias veces. Eso es lo que significa la variabilidad: la opción de utilizar los datos con distintos fines.
¿Cómo funciona el Big Data?
La idea principal del Big Data es que permite tener acceso a más información. Y cuanta más información se tiene, mayor es el entendimiento y mejor se pueden tomar decisiones o buscar soluciones.
En muchos casos, el proceso de análisis de los datos está totalmente automatizado, es decir, se disponen de herramientas tan avanzadas que crean millones de simulaciones para obtener el mejor resultado posible. Pero para conseguirlo con la ayuda de las herramientas analíticas, el aprendizaje automático o incluso la inteligencia artificial, hay que saber cómo funciona el Big Data y configurar cada elemento correctamente.
La necesidad de gestionar tantos datos requiere una infraestructura estable y bien estructurada. ¿Por qué? Puesto que es necesario procesar rápidamente grandes volúmenes de datos y tipos de datos diferentes, un único servidor o clúster se puede sobrecargar.
Por eso, los científicos de datos necesitan un sistema bien pensado para gestionar el Big Data, que tenga una capacidad suficiente para soportar todos los procesos necesarios. Y en el caso de las grandes empresas, pueden hacer falta cientos o miles de servidores. Como te imaginas, esto puede salir caro. Y cuando añades todas las herramientas que se requieren, todavía se encarece más.
Para crear el mejor sistema posible y elaborar un presupuesto de antemano, es necesario saber cuáles son las tres acciones principales que se realizan con las grandes cantidades de datos.
Integración
El Big Data normalmente procede de diversas fuentes y, puesto que se trata de volúmenes enormes de información, hace falta descubrir estrategias y tecnologías para poder recibir los datos de manera eficiente. En algunos casos, decenas de petabytes de información llegan al sistema de una empresa, por lo que integrar toda esta información en un sistema es todo un reto. Es necesario recibir los datos, procesarlos y formatearlos de la manera más adecuada para cada empresa y, de tal forma que los clientes puedan entenderlos.
Gestión
Los datos necesitan estar en algún lugar, y aquí es donde entran en juego las soluciones de almacenamiento de datos. Estas soluciones pueden estar en la nube, en las instalaciones de una empresa o en ambas. También se puede elegir de qué forma almacenar los datos, de modo que estén disponibles en tiempo real o no. Cada vez más organizaciones y personas eligen una solución en la nube para almacenar los datos, que les permite poder tener acceso en cualquier momento y es compatible con su infraestructura informática.
Análisis
Tras recibir los datos y almacenarlos, el siguiente paso es el análisis del Big Data. Los datos se analizan y utilizan para tomar decisiones importantes, como definir la oferta de una organización según las preferencias de los clientes. Cada organización utilizará los datos con fines distintos para sacar el mayor provecho posible y obtener una ventaja competitiva. Y es que la inversión que el Big Data requiere no es una broma, por lo que sus resultados deben generar valor y beneficios para los clientes y para la propia organización.
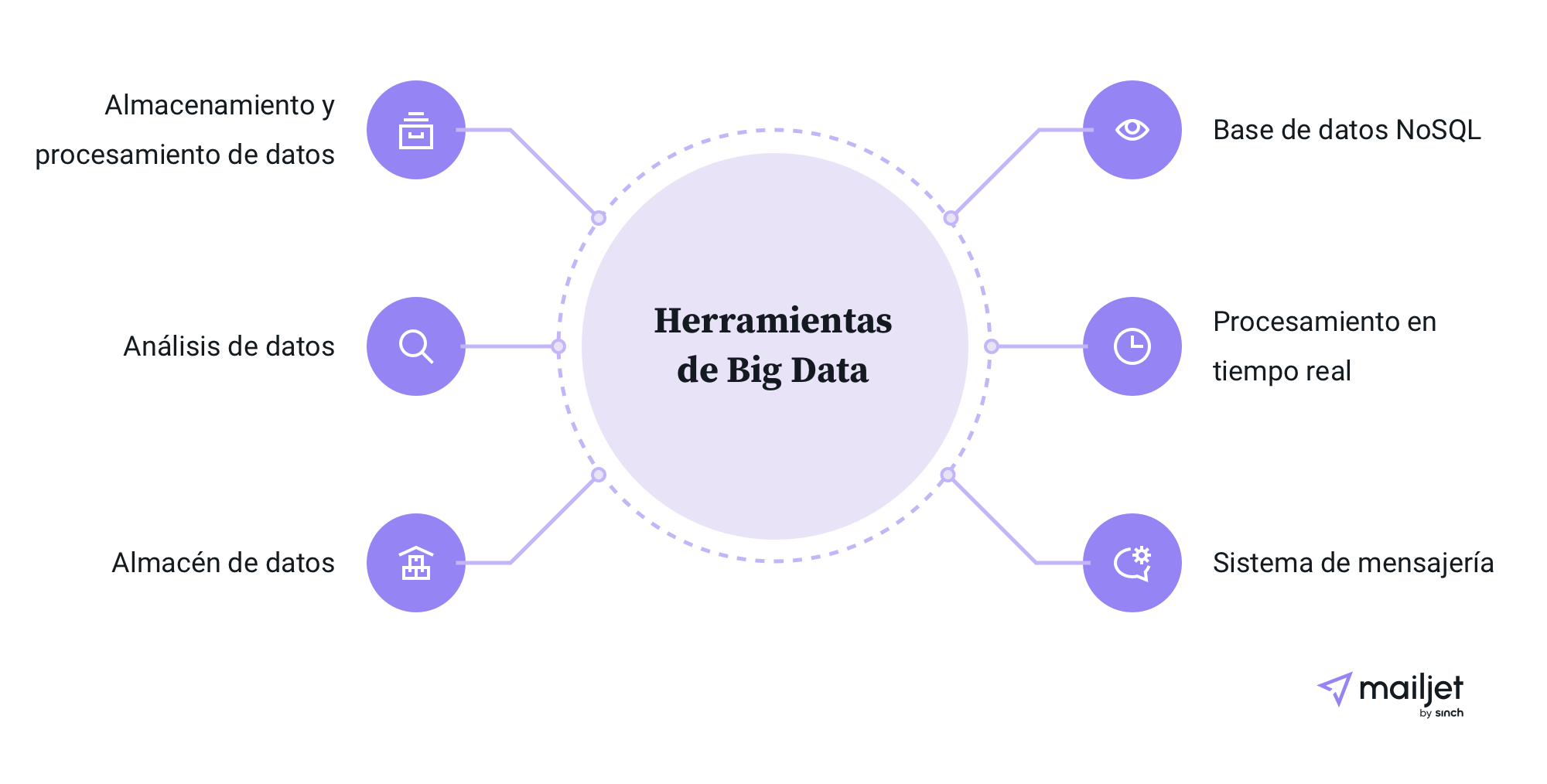
Herramientas de Big Data
Puesto que el Big Data no deja de crecer, las herramientas que se usan para gestionarlo también crecen y evolucionan permanentemente. Las organizaciones utilizan herramientas como Hadoop, Pig, Hive, Cassandra, Spark o Kafka, dependiendo de los requisitos específicos que tengan. La fundación Apache Software Foundation (ASF) apoya muchas de estas herramientas de Big Data.
Buena parte de estas herramientas son de código abierto y, puesto que son vitales para procesar el Big Data, vamos a explicar brevemente las principales características de las más populares:
Apache Hadoop: Una de las soluciones más conocidas para analizar Big Data, que utiliza un marco de trabajo de código abierto para almacenar y procesar grandes conjuntos de datos.
Apache Spark: Esta herramienta permite almacenar gran parte de los datos de procesamiento en la memoria y en el disco, lo que se traduce en una mayor rapidez. Trabaja con los lenguajes de programación Java, Scala, Python, R y SQL y funciona con el sistema de archivos distribuidos de Hadoop (HDFS), Apache Cassandra, OpenStack Swift y muchas otras soluciones de almacenamiento de datos.
Apache Kafka: Esta solución permite a los usuarios publicar y suscribirse a fuentes de datos en tiempo real. La principal tarea de Kafka es trasladar la fiabilidad de otros sistemas de mensajería a los datos en streaming.
Apache Lucene: Una herramienta que puede usarse para cualquier motor de recomendación porque utiliza bibliotecas de software de indexación y búsqueda de textos completos.
Apache Zeppelin: Un proyecto que permite el análisis de datos interactivos con SQL y otros lenguajes de programación.
Elasticsearch: Se podría definir como un motor de búsqueda empresarial, que destaca porque puede aportar conocimientos a partir de datos estructurados y no estructurados.
TensorFlow: Una plataforma de machine learning cada vez más popular que se utiliza con fines de aprendizaje automático.
El Big Data seguirá creciendo y cambiando y, por lo tanto, las herramientas también lo harán.
Ya sabemos muchas cosas sobre el Big Data: cuáles son las grandes “V”, cómo funciona y cuáles son algunas de las herramientas más populares. Veamos ahora cuáles son los usos del Big Data, uno de nuestros apartados favoritos.
Usos del Big Data
Tanto las personas como las máquinas pueden analizar los datos del Big Data a través del uso de distintos métodos analíticos. Estos métodos permiten combinar distintos tipos y fuentes de datos para obtener información precisa y tomar decisiones relevantes. Veamos algunos de los usos más habituales del Big Data.
Desarrollo de productos
A partir de productos anteriores o actuales, las empresas pueden crear modelos predictivos para nuevos productos y servicios a través de la clasificación de atributos clave. ¿Cómo crees que Netflix te envía un mensaje con recomendaciones especialmente elegidas para ti cada semana? Correcto, con la ayuda del análisis de Big Data, Netflix y otras organizaciones utilizan modelos predictivos y te informan de las novedades que te pueden gustar clasificando los datos del pasado y los programas que has visto o marcado como favoritos.
Hay empresas que también utilizan otros recursos, como información de redes sociales, información de ventas de las tiendas o encuestas, para predecir cuál es la mejor manera de lanzar un nuevo producto o dirigirlo a las personas más adecuadas.
Análisis comparativo
Cuando se sabe cómo se comportan los clientes y se pueden observar en tiempo real, es posible comparar sus patrones con los itinerarios que han seguido para otros productos parecidos e identificar cuáles son las fortalezas de una organización frente a sus competidores.
También es útil a la hora de realizar análisis comparativos en distintos mercados, como el inmobiliario, donde tener una gran cantidad de datos disponible para poder analizar puede significar una ventaja competitiva inmediata.
Experiencia del cliente
El Big Data permite recopilar datos de redes sociales, visitas en internet, registros de llamadas y otras fuentes para mejorar la experiencia de los clientes a través de la personalización y la toma de decisiones. Si, por ejemplo, la tasa de abandono de carritos en un mercado internacional es mucho mayor que en el mercado doméstico, esto podría deberse a las preferencias de pago de los usuarios en el país. El Big Data permite analizar a los usuarios para tomar medidas que mejoren su experiencia.
Aprendizaje automático
El aprendizaje automático o machine learning utiliza el Big Data para desarrollar modelos de aprendizaje automático gracias a la inteligencia estadística y computacional, que analiza grandes cantidades de información con un mínimo de o sin supervisión humana. Este es el caso, por ejemplo, de los sistemas de traducción automática que utilizan tecnologías de aprendizaje automático para traducir textos.
Si además unimos el machine learning con el análisis del bienestar de los usuarios, nos encontramos con iniciativas como la del Metro de Barcelona, que empezó a utilizar una IA en 2020 para mejorar la ventilación y ayudar con el control de infecciones por coronavirus.
Escalabilidad y predicción de fallos
A través del análisis de datos estructurados (periodos de tiempo, equipos) y no estructurados (entradas de registros, mensajes de error, etc.) es posible predecir fallos o la demanda futura de una organización. Este uso del Big Data permite prevenir posibles problemas antes de que se produzcan, como puede verse en esta prueba de concepto llevada a cabo por PredictLand.
Fraude
El Big Data ayuda a identificar patrones de datos que son indicios de fraude con el objetivo de prevenirlos. Por ejemplo, las entidades bancarias pueden detectar si los comportamientos de los usuarios son o no normales, como hacen desde 2017 tres de los principales bancos españoles: Santander, BBVA y CaixaBank.
¿Por qué es el Big Data tan importante?
El Big Data tiene un potencial enorme y es importante para el progreso de la tecnología. Las organizaciones que usan Big Data son capaces de tomar decisiones comerciales más rápido y con mejor criterio, por ejemplo, personalizando productos, contenidos e itinerarios según las preferencias de sus clientes. Pero eso no es todo. Las empresas pueden incluso predecir con exactitud qué segmentos de sus clientes pueden querer sus productos y en qué momento, lo que les permite lanzar sus campañas de publicidad en el instante oportuno.
Y como hemos visto, las aplicaciones son casi infinitas. Los fallos o errores mecánicos pueden minimizarse porque se pueden predecir las condiciones en las que se producen. Un coche que conduce solo puede ser más seguro que los vehículos convencionales porque no comete errores humanos. Tu compañía de telefonía móvil puede enviarte ofertas con los dispositivos que más te gustan.
Además, no es solo cuestión de las distintas aplicaciones que tiene el uso de big data, sino también de las nuevas oportunidades que han generado los proyectos de Big Data en los últimos años.
Por ejemplo, en España, la demanda de profesionales relacionados con el sector de los macrodatos lleva a que, a día de hoy, sea un sector sin paro. Y las universidades no se quedan atrás, con varias de ellas ofreciendo másteres en análisis de macrodatos y data science (ciencia de datos).
¿Cuál es el futuro del Big Data?
El Big Data ya está cambiando la manera en la que las organizaciones y las personas toman sus decisiones y, sin duda, sus efectos serán todavía más evidentes en el futuro. Cuando (casi) todo lo que tenemos a nuestro alrededor usa internet (el Internet de las Cosas), las posibilidades de utilización del Big Data son tremendas.
Por ejemplo, empresas como la consultora PwC en su informe Trabajar en 2033 ya aventuran que varias de las profesiones de la siguiente década estarán relacionadas con el Big Data. En esa línea, ya existen iniciativas por parte de distintas administraciones, como la de Córdoba, para formar a los jóvenes en las destrezas necesarias para ocupar estos puestos de trabajo.
La cantidad de datos que tenemos a nuestra disposición no hace más que aumentar, y las herramientas que se utilizan para el Big Data también evolucionarán, adaptándose a nuevos requisitos. Es probable que en los próximos años el almacenamiento y la gestión de datos a gran escala se hagan de forma que requieran menos espacio y recursos, para reducir costes y facilitar su tratamiento.
Big Data e inteligencia artificial, un futuro prometedor
Con el desarrollo de las IA en los últimos años se han creado nuevas oportunidades en torno al Big Data (tanto en la integración, como en la gestión y el análisis), por lo que sigue siendo un campo en expansión. Se presentan nuevas herramientas basadas en IA casi cada mes y existen eventos dedicados como el Big Data & AI World, en Madrid.
En definitiva, el Big Data ya está dando forma al futuro de la humanidad. Y en Sinch Mailjet utilizamos el Big Data y la inteligencia artificial para ofrecer el mejor servicio posible a nuestros usuarios con herramientas como estas.
Mailjet
Diseña emails increíbles con Mailjet
Crea fácilmente campañas increíbles con nuestro potente editor de emails y envía mensajes que lleguen a la bandeja de entrada.
El alcance y las posibilidades del Big Data habrían parecido impensables hace unos años. Pero hoy en día casi cualquier otra innovación tecnológica está influenciada por el Big Data.
Eso sí, seamos honestos, entender lo que es y cómo funciona el Big Data no es algo fácil. No importa cómo de bien hayamos intentado explicarlo. Como sabemos que es mucha información que retener, hemos resumido los puntos principales en una infografía que esperamos que sea útil.
***
Este artículo es una versión actualizada del artículo ¿Qué es el Big Data y cómo funciona?, de Gabriela Gavrailova, que se publicó en el blog de Mailjet en diciembre de 2019.
La mayoría de la gente estaría de acuerdo en que las cookies mejoran su vida. En nuestro caso, nos ayudan a mejorar nuestra página web y nuestros esfuerzos de marketing. Pero si no te gustan las cookies, no pasa nada: Puedes hacérnoslo saber haciendo clic en el botón de ajustes.
Tu selección de cookies
Cuando visita un sitio web, este puede almacenar o recuperar información en su navegador, principalmente en forma de cookies. Esta información puede ser sobre usted, sus preferencias o su dispositivo y se utiliza principalmente para lograr que el sitio funcione como se espera. La información generalmente no lo identifica en forma directa, pero puede brindarle una experiencia web más personalizada. Como respetamos su privacidad, puede optar por excluir algunos tipos de cookies. Puede hacer clic en los diferentes encabezados de categoría para obtener más información y cambiar nuestra configuración predeterminada. Sin embargo, si bloquea algunos tipos de cookies, su experiencia de uso en el sitio se puede ver afectada y también los servicios que podemos ofrecerle. Declaración sobre cookies
Estas cookies son necesarias para que el sitio web funcione y no se pueden desactivar en nuestros sistemas. Usualmente están configuradas para responder a acciones hechas por usted para recibir servicios, tales como ajustar sus preferencias de privacidad, iniciar sesión en el sitio, o llenar formularios. Usted puede configurar su navegador para bloquear o alertar la presencia de estas cookies, pero algunas partes del sitio web no funcionarán. Estas cookies no guardan ninguna información personal identificable.
Detalles de las cookies
Estas cookies nos permiten contar las visitas y fuentes de circulación para poder medir y mejorar el desempeño de nuestro sitio. Nos ayudan a saber qué páginas son las más o menos populares, y ver cuántas personas visitan el sitio. Toda la información que recogen estas cookies es agregada y, por lo tanto, anónima. Si no permite estas cookies no sabremos cuándo visitó nuestro sitio, y por lo tanto no podremos saber cuándo lo visitó.
Detalles de las cookies
Estas cookies permiten que el sitio ofrezca una mejor funcionalidad y personalización. Pueden ser establecidas por nosotros o por terceras partes cuyos servicios hemos agregado a nuestras páginas. Si no permite estas cookies algunos de nuestros servicios no funcionarán correctamente.
Detalles de las cookies
Estas cookies pueden estar en todo el sitio web, colocadas por nuestros socios publicitarios. Estos negocios pueden utilizarlas para crear un perfil de sus intereses y mostrarle anuncios relevantes en otros sitios. No almacenan información personal directamente, sino que se basan en la identificación única de su navegador y dispositivo de acceso al Internet. Si no permite estas cookies, tendrá menos publicidad dirigida.
Detalles de las cookies
Estas cookies están configuradas por una serie de servicios de redes sociales que hemos agregado al sitio para permitirle compartir nuestro contenido con sus amigos y redes. Son capaces de hacerle seguimiento a su navegador a través de otros sitios y crear un perfil de sus intereses. Esto podrá modificar el contenido y los mensajes que encuentra en otras páginas web que visita. Si no permite estas cookies no podrá ver o usar estas herramientas para compartir.
Detalles de las cookies